第8课
从零构建嵌入
- 第二部分会是什么样的感觉?技术上会更深入吗?能够阅读和实现研究论文吗?模型会涉及真实生活场景吗?
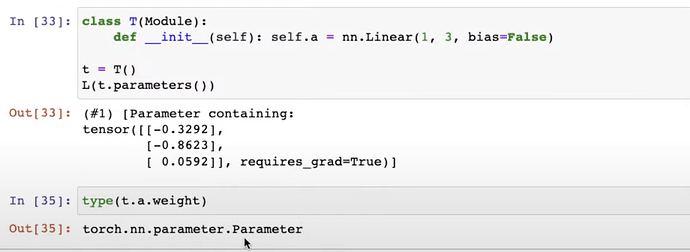
- 回顾从零构建神经网络。PyTorch 如何轻松创建神经网络?PyTorch 如何通过
Module跟踪模型权重?Module如何使用nn.Parameter存储权重?如何使用parameters()从模型中检查权重?

- 你可以在 Module 中使用
nn.Linear构建层而无需nn.Parameter,PyTorch 也能从中读取权重。
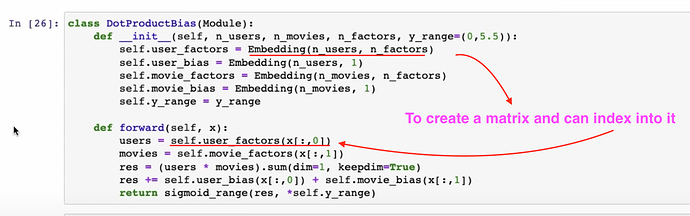
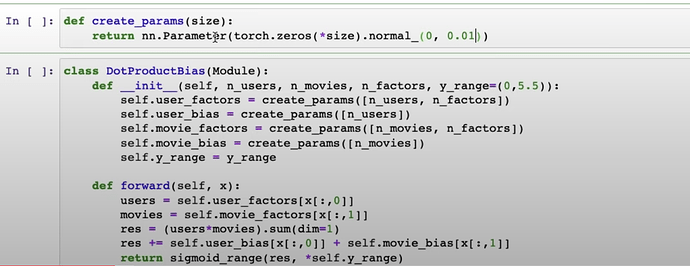
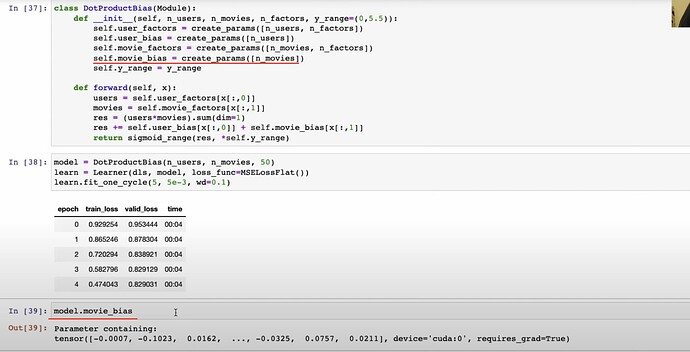
- 如何使用
create_params从零开始用 PyTorch 创建Embedding函数和整个DotProductBias?训练完成后,可以检查训练好的movie_bias。你可以通过model.movie_bias.shape检查偏置的形状。
- 问题:
Tensor.normal_的作用是什么?


嵌入的解释
- 训练后,
movie_bias能告诉我们关于每部电影和所有电影的什么信息?低偏置对电影意味着什么?高偏置对电影意味着什么?user_bias能告诉我们哪些用户即使是烂片也喜欢看吗?这是对movie_bias的可视化。

- 我们如何解释形状为
(num_users, 50)的巨大矩阵或对其进行处理?如何使用pca将 50 个潜在因子缩减为最重要的 3 个因子?
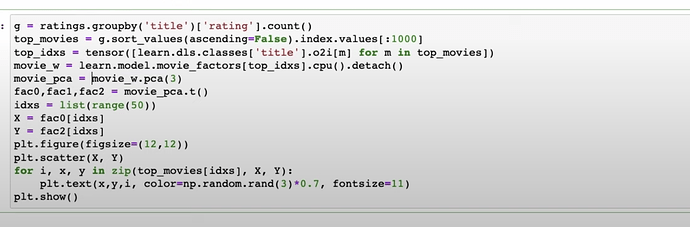
- 如何解释仅使用通过 50 个因子压缩而来的 3 个 PCA 因子中的两个对电影进行评分的 PCA 图表?电影的品味或风格如何被浓缩为两个因子,并由二维图表中的位置来显示和定义?这是电影因子或嵌入的可视化。

- fastai 如何只需一行代码就能让上述所有工作变得更简单?
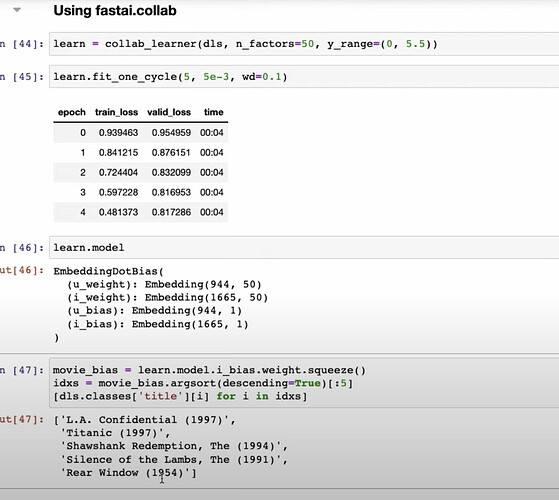
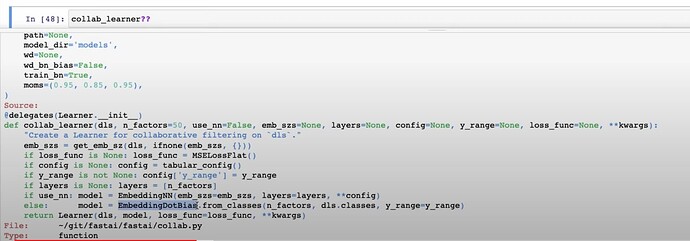
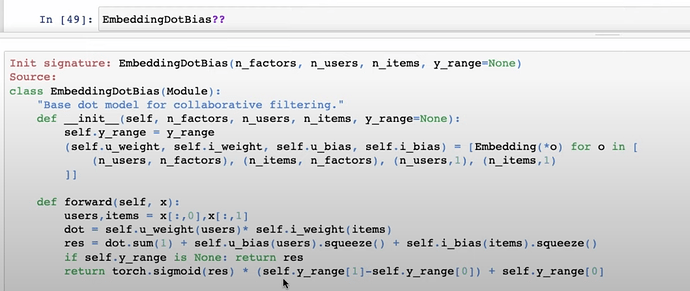
- fastai 是如何在
collab_learner的底层构建一切的?
- 问题:PCA 在其他应用中有用吗?在哪里可以找到更多关于 PCA 的信息?为什么你应该学习 Rachel 的计算线性代数课程?
- 如何使用嵌入距离来找出电影的相似度?
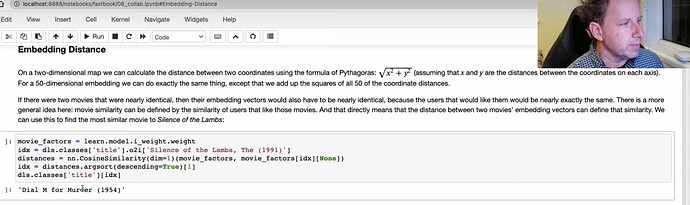
- 阅读 fastbook 学习如何引导构建协同过滤模型
用于协同过滤的深度学习
- 如何使用深度学习而不是上面用点积进行的矩阵填充来做协同过滤?如何将最简单的神经网络模型架构应用到协同过滤的案例中?
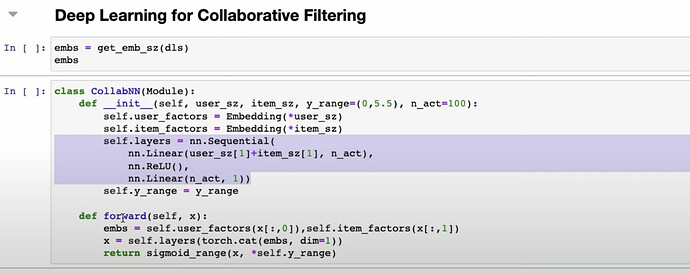
- fastai 如何使用经验法则来推荐用户和电影的潜在因子数量?

- fastai 如何通过两种方式使用深度学习来构建协同过滤模型?
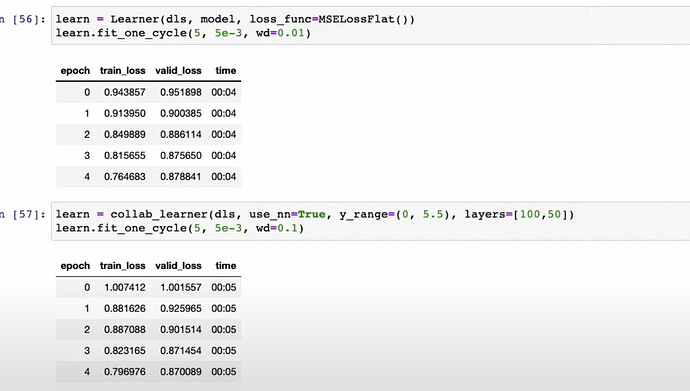
为什么深度学习版本不如 DotProduct 版本?是因为 DotProduct 更适用于该问题吗?公司如何结合这两种版本来做协同过滤?当你有很多元数据时,应该对其应用深度学习吗?你如何在模型中使用元数据? - 问题:少数用户和电影会压倒其他人吗?例如,一小群动漫爱好者看了大量动漫电影并给出超高评分。此处不讨论如何处理这些细节 - 如何通过电子表格演示将嵌入矩阵应用到 NLP 模型中?神经网络的本质是什么?
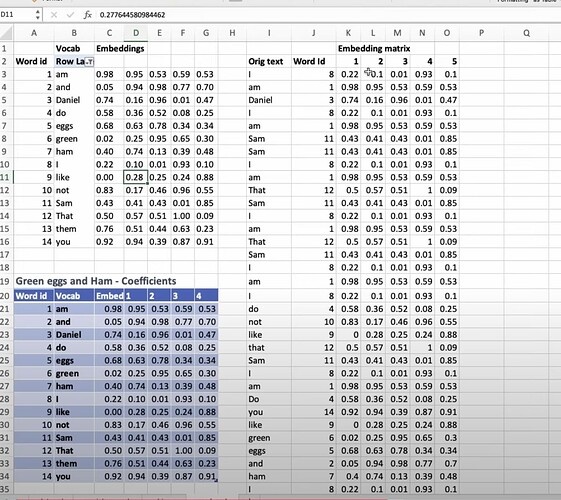
- 如何将嵌入应用于表格数据集和模型?如何理解
TabularModel和tabular_learner的源代码? - 通过一个商店销售预测的 Kaggle 竞赛以及基于此发表的一篇论文,了解神经网络内部正在发生什么?
卷积
- 到目前为止,我们已经了解了作为输入的进入模型的内容以及作为输出的模型输出的内容。我们也了解了中间部分的矩阵乘法。什么是卷积(中间的一种特定类型的矩阵乘法)?它为什么对 CV (计算机视觉) 非常有用?为什么 MNIST 是最著名的 CV 数据集之一?Jeremy 如何使用 Excel 和卷积将 Fergus 和 Zeiler 的论文内容应用到 MNIST 上?
- 如何理解卷积?过滤器有什么作用?它如何帮助检测水平和垂直边缘?如何确定过滤器或核的大小(3x3、5x5 或其他任何大小)?conv1 表示第一个卷积层。
- 进入第二个卷积层。两个过滤器在第一个卷积层中产生两个通道。在第二个卷积层中,我们创建一个 3D 矩阵过滤器,它包含两个矩阵过滤器来过滤/处理第一个卷积层输出的两个通道,并压缩数值。我们也可以使用另一个 3D 过滤器为第二个卷积层创建第二个通道。
- 如何确定输出并使用 SGD 训练模型和优化过滤器?
- 什么是最大池化 (maxpooling)?最大池化有什么问题?我们丢失了多少数据?为什么这是一件好事?什么是全连接层 (dense layer)?它的作用是什么?
- 如今我们做卷积有什么细微的不同?什么是步长为二的卷积 (stride-two convolution)?它是如何工作的?(不再使用最大池化)然后我们进行多次步长为二的卷积,直到尺寸缩小到 7x7,然后进行
average_pooling(不再使用全连接层)。7x7 网格并取平均值意味着什么?这种方法有什么问题?何时更适合使用最大池化?fastai 如何通过发明一种称为concat_pooling的技术,将最大池化和平均池化结合起来,使我们能够轻松尝试两种池化方式? - 如何从矩阵乘法的角度理解卷积?
- 什么是 Dropout?如何使用 Excel 理解它?什么是 Dropout 掩码?它在 Excel 中直观的效果是什么?如何将 Dropout 理解为激活函数的数据增强?它如何帮助避免过拟合?Dropout 和学术界的故事是什么?
- 为什么 Jeremy 没有花很多时间在激活函数上?我们已经看到了许多关于指标、损失和激活的函数。
- 在开始 fastai 第二部分之前接下来做什么?Radek 的元学习书是关于什么的?在“写、帮助、收集、构建 (Write, Help, Gather and Build)” 中要做的事情是什么?
- 一位 fastai 社区成员发表了 Mish 激活函数,许多最先进的模型都在使用它。
Jeremy AMA
- 如何跟上步伐?通过专注于深度学习的子领域以及那些变化不大的基础知识来跟上,例如 fastai 的基础在过去 5 年里变化不大。其他的一切都只是微调。
- 巨大的数据集和 GPU 计算会取代使用小数据集和单 GPU 的我们吗?总有更巧妙的方法做事,例如 fastai 团队在标准 GPU 上训练 ImageNet 比拥有大量 GPU 的公司更快。选择不同领域的方向,在这些领域中较小的模型也能超越最先进的水平。
- Jeremy 如何教孩子们数学?所有孩子都可以用 dragonbox5+ 学习代数。太好了,Jeremy 承诺稍后会更多地谈论如何教孩子。
- 演练计划
- 如何将模型转化为商业?好消息,Jeremy 计划为此开设一门课程!创业的起点是什么?第一步是什么?如何逐步弄清楚你的想法是否真正符合人们的需求?
- Jeremy 如何保持如此高效的工作?把事情做得漂亮,持之以恒。