第7课
梯度累积与 GPU 内存
- 在之前的课程中,我们探讨了具有全连接线性层的最简单的神经网络。在本课程中,我们将重点关注调整第一层和最后一层,在接下来的几周里将关注调整神经网络的中间部分。
- 回顾笔记本 Road to Top part 2(通往顶峰之路 第2部分)并祝贺 fastai 学生击败 Jeremy 获得第一名和第二名
- 使用更大的模型有什么好处?更大的模型有什么问题?(会占用 GPU 内存,因为 GPU 不像 CPU 那样擅长寻找释放内存的方法;所以大型模型需要非常昂贵的 GPU)当 GPU 内存不足时我们可以怎么做?首先,重启笔记本;然后 Jeremy 将向我们展示一个技巧,使我们能够在 Kaggle 上训练超大型模型,哇!
- Kaggle 的 GPU 有多大?有时候你必须在 Kaggle 上运行笔记本吗?例如在代码竞赛中?为什么使用 Kaggle 笔记本赢得排行榜是好的和公平的?
- Jeremy 是如何使用 24G GPU 来弄清楚 16G GPU 可以做什么的?Jeremy 是如何找出模型会使用多少 GPU 内存的?Jeremy 是如何选择最小的图像子集作为训练集的?训练模型更长时间会占用更多内存吗?(不会)所以,最小的训练集 + 训练一个 epoch 可以快速告诉我们模型需要多少内存。
- 然后 Jeremy 训练了不同的模型,看看它们占用了多少内存。convnext-small 模型需要多少内存?Jeremy 使用哪行代码来找出模型占用的 GPU 内存?Jeremy 使用哪两行代码来释放非必要占用的 GPU 内存,这样你就不需要重启内核来运行下一个模型?
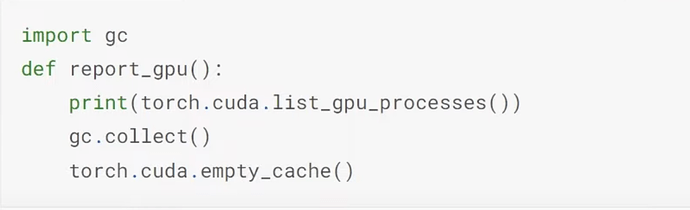
- 如果模型导致 cuda 内存不足的崩溃问题怎么办?什么是梯度累积(Gradient Accumulation)?什么是整除?(
//)。
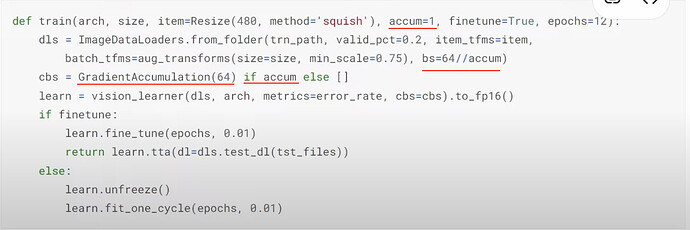
- 使用更小的批量大小有什么问题?(批量大小越小,学习率和权重的波动性越大)我们如何让模型在更小的批量大小下训练,就像在大型批量大小下一样?如何在代码中解释梯度累积(Gradient Accumulation)?


- 使用梯度累积(Gradient Accumulation)有什么影响?使用和不使用梯度累积(Gradient Accumulation)的数值结果有多大差异?造成差异的主要原因是什么?
- 更多问题:在上面的代码中进行梯度累积(Gradient Accumulation)时,应该是
count >= 64;lr_find使用 DataLoader 中的批量大小; - 为什么不直接使用更小的批量大小而不是梯度累积(Gradient Accumulation)?选择批量大小的经验法则是什么?根据批量大小调整学习率怎么样?
- Jeremy 是如何使用梯度累积(Gradient Accumulation)来找出在 Kaggle 的 16G GPU 上运行这些大型模型需要多少
accum的?(accum=1总是内存不足,但accum=2对所有大型模型都有效)。

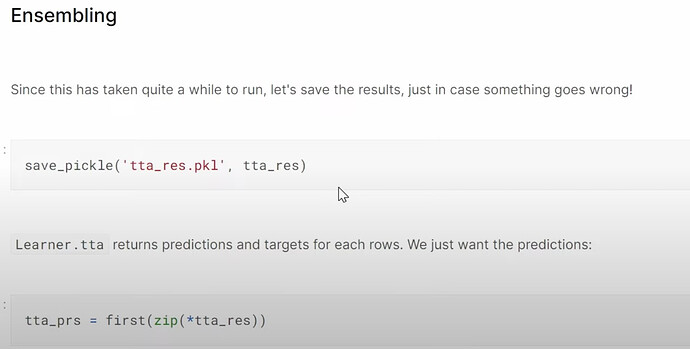
创建集成模型
- Jeremy 是如何将所有模型及其设置放在一起,以便稍后进行实验的?我们现在必须使用模型的规格大小吗?将来呢?
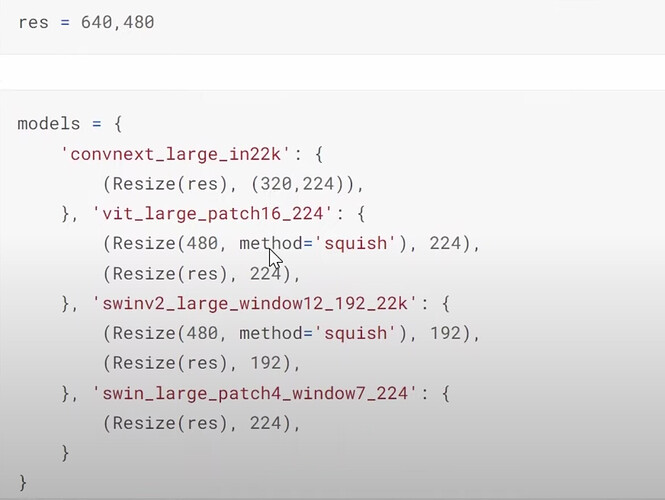

- 如何在不内存不足的情况下运行所有带规格的模型
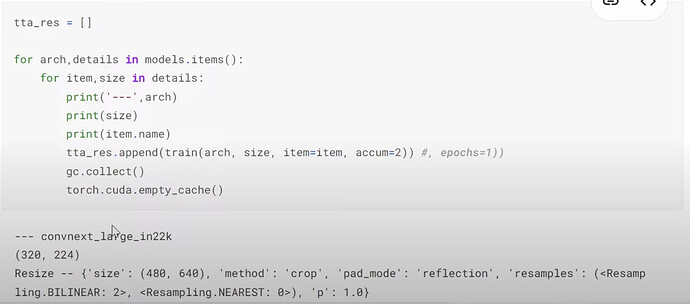
- 为什么 Jeremy 在这里训练时不使用
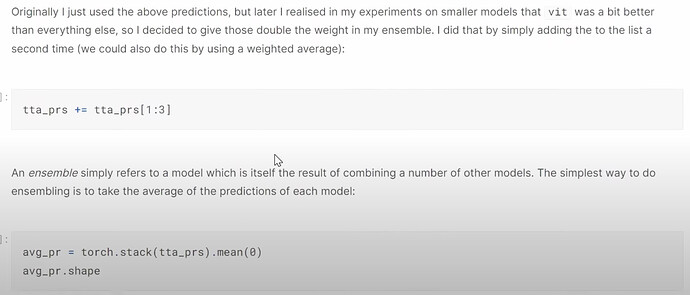
seed=42?有什么影响? - 什么是集成或 bagging 不同的优秀深度学习架构?为什么它有用?
- 如何对不同的深度学习模型进行集成?
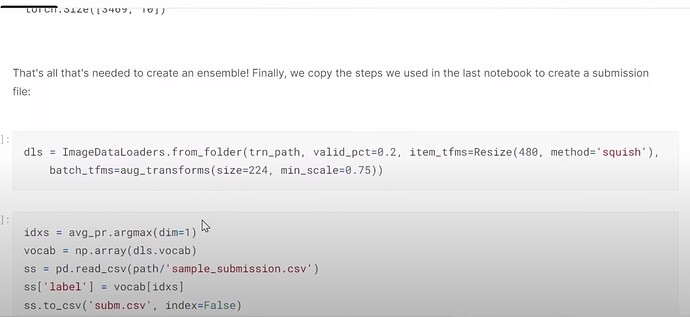
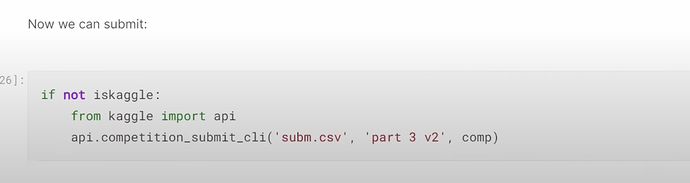
- 为什么我们应该每天改进并提交到 Kaggle?提交历史如何帮助跟踪你的模型开发和改进?
- 更多问题:什么是 k 折交叉验证?如何在这种情况下应用?为什么 Jeremy 不使用它?
- 梯度累积(Gradient Accumulation)有什么缺点吗?有没有 GPU 推荐?
- 在第2部分,Jeremy 可能会介绍如何训练一个较小的模型,使其像大型模型一样表现良好,以便实现更快的推理
多目标模型
- 如何设置数据分割以及项目和批量转换?
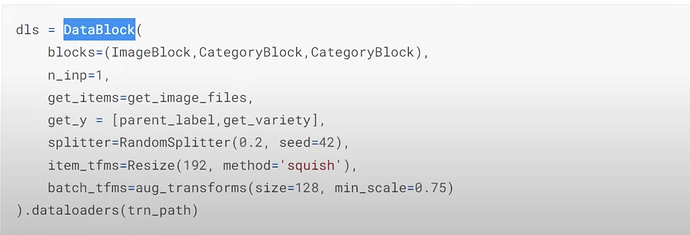
- 如何创建一个模型来预测疾病和品种类型?我们可以将预测疾病和品种看作是预测 20 件事物,其中 10 件是疾病,10 件是品种吗?
- 新模型(和新的 dataloaders)现在需要什么才能对疾病进行预测?

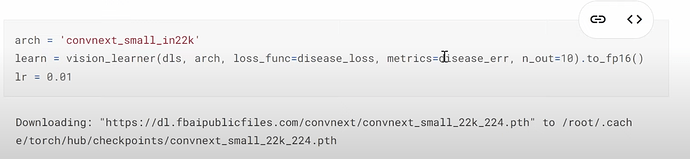
- 何时以及如何提供我们自己的损失函数?fastai 可以在简单情况下检测适用于你的 dataloaders 的损失并默认使用。在这种特殊情况下,我们如何为新模型创建和使用自定义损失?
交叉熵与 Softmax
F.cross_entropy具体做什么?这个函数属于第一层和最后一层,因此我们必须理解它们。预测 5 件事物的模型的原始输出是什么?
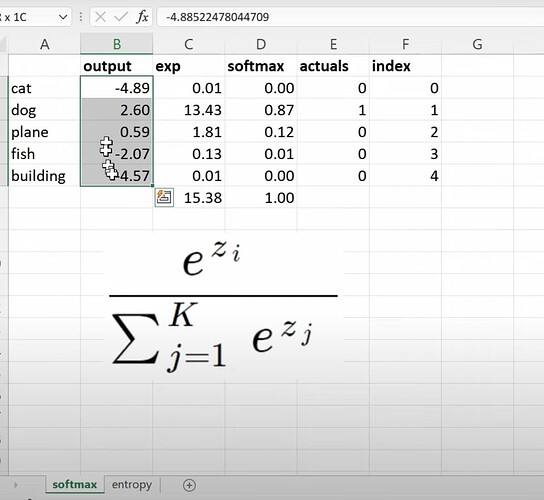
- Softmax 的公式是什么?如何在电子表格中计算它?
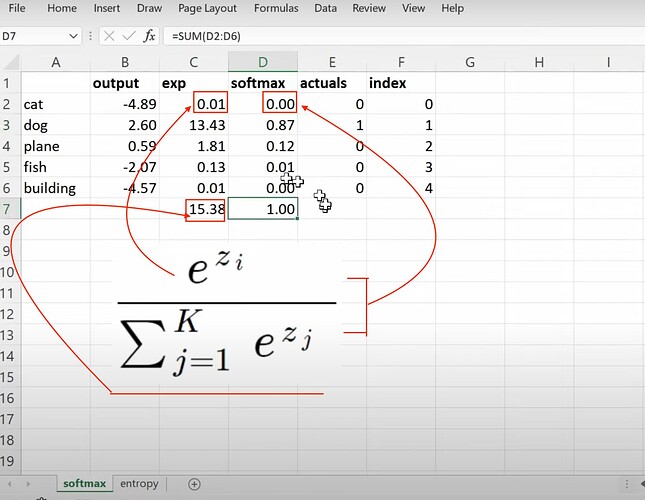
- Softmax 有什么问题?当给熊分类器一张猫的图像时,它如何做出明显的错误预测?
- 对于上面的 Softmax 问题我们可以做些什么?(所有预测概率之和不等于 1)。你何时使用 Softmax?何时不使用?
- 交叉熵损失公式的第一部分是什么?

- 如何从 Softmax 计算交叉熵?
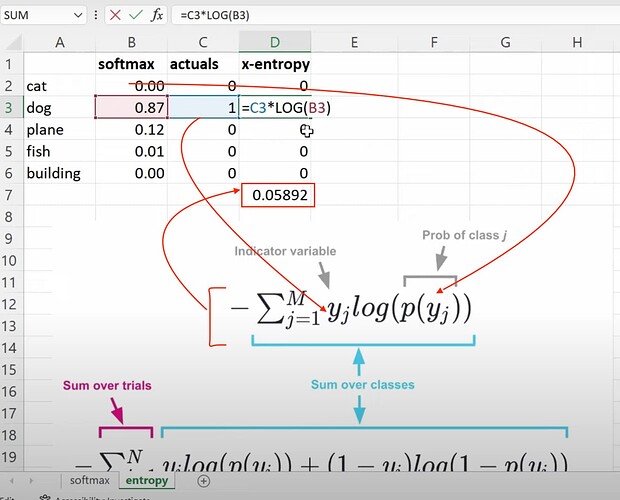
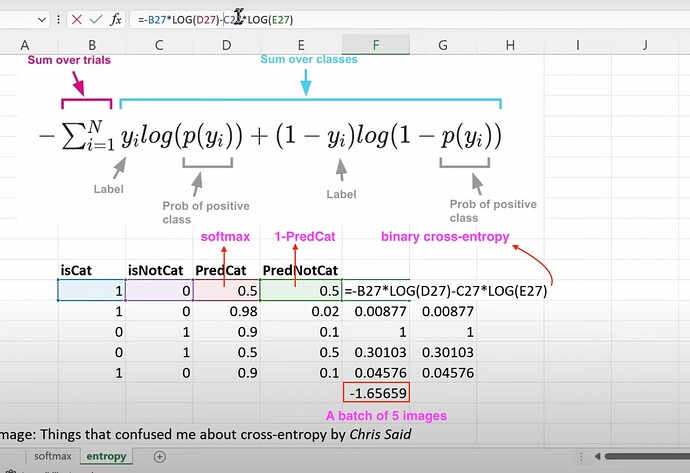
- 如何计算二元交叉熵?如何理解它在预测是否是猫或非猫图像时的公式?最终如何获得包含 5 张图像的批次的二元交叉熵损失?
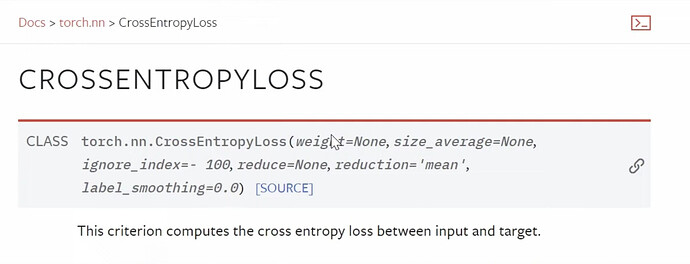
- pytorch 中交叉熵的两个版本是什么?何时使用每个版本?我们在这里使用哪个版本?

多目标激活函数
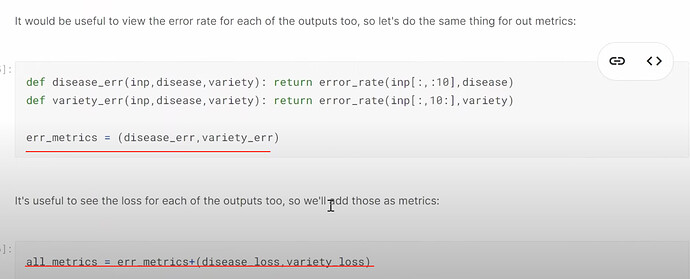
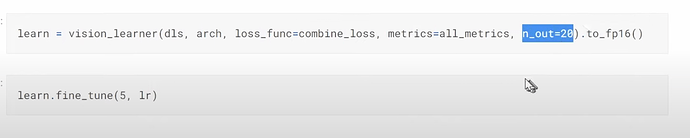
- 当 dataloader 有两个目标时,我们的新模型需要知道损失函数、指标以及输出的大小具体是什么?
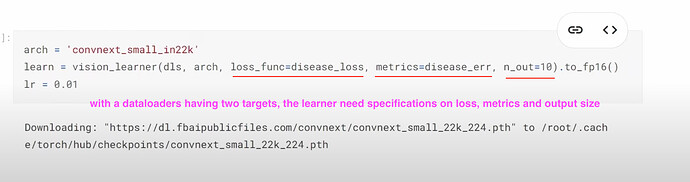
- 如何为预测两个目标或 20 个项目创建一个 learner?learner 如何使用疾病和品种损失来知道哪 10 个项目是疾病预测,哪 10 个是品种预测?如何将两个损失函数组合在一起?如何理解组合损失?




- 如何计算疾病类型和品种类型的错误率?如何在训练期间将它们组合在一起并显示?
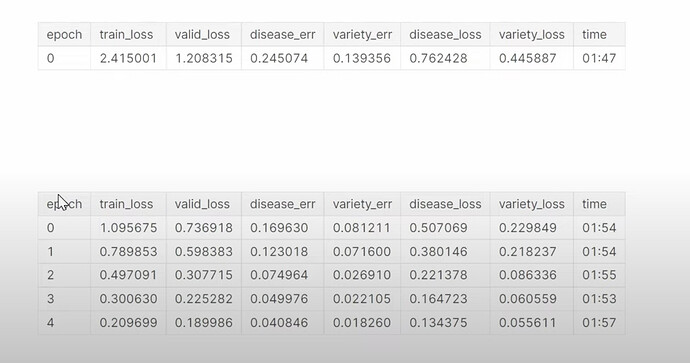
- 如何创建新的 learner 以及它是如何训练的?为什么多任务模型没有改进,甚至比之前的模型稍差?为什么训练多任务模型更长时间可以提高疾病预测的准确性?为什么同时预测第二件事可以帮助提高第一件事的预测?Jeremy 之前参加的一个 Kaggle 鱼类预测竞赛中使用多任务模型确实改进了结果。构建多任务模型的原因或好处是什么?
如何让你对多任务建模不那么困惑?(从头开始为 Titanic 数据集构建一个多任务模型;探索并实验由 Chris Said 提供的二元交叉熵笔记本)?
协同过滤
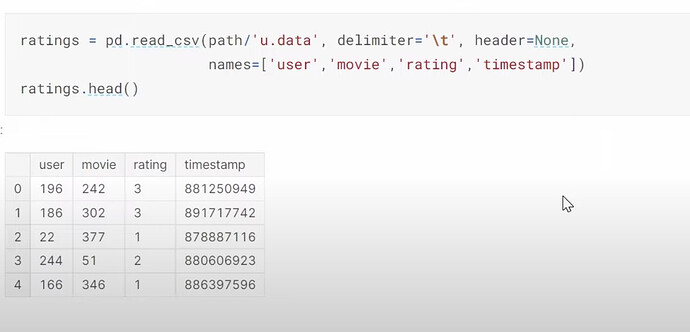
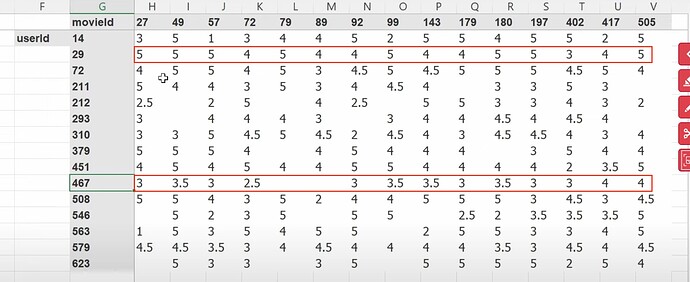
- 协同过滤深入探讨,作为第 8 章不变。使用了哪个数据集?我们使用的数据是哪个版本?如何使用 pandas 读取 tsv 文件?如何读取/理解数据集内容/列?推荐系统行业和 Radek。Jeremy 喜欢如何查看数据?(交叉表格)为什么 Jeremy 谈论他首选的数据查看方式的图像中只有很少的空数据或缺失数据?

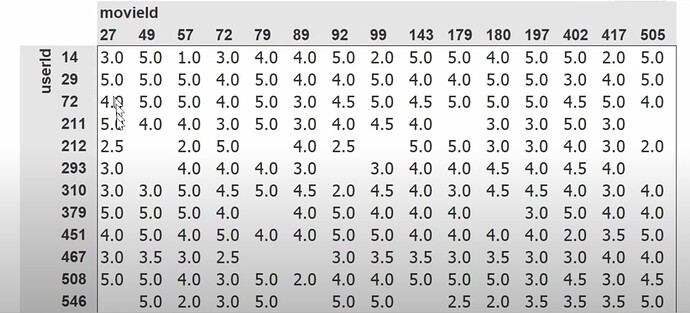
- 如何填充交叉表格数据集中的缺失数据或空白?如何确定一个新用户是否会喜欢他/她之前没有看过的特定电影?我们能找出我们在这里讨论的特定电影是什么类型/流派的吗?电影的类型概率是什么样子的?用户的偏好概率是什么样子的?如果我们匹配这两组概率,我们能知道用户有多喜欢这部电影吗?我们如何计算?

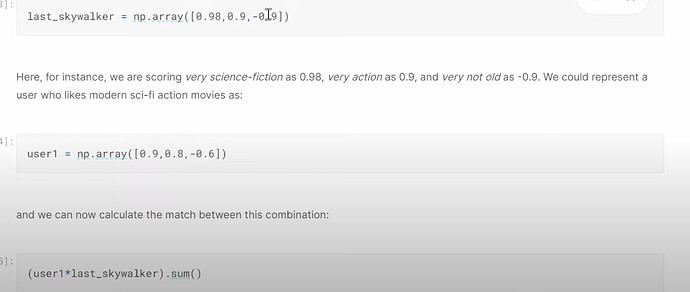

- 到目前为止都很好,使用用户偏好概率和电影类型概率进行点积来找出新用户对电影的评分的方法有什么问题?(我们不知道这两种概率)。我们将如何处理这个问题?我们能在甚至不知道类型的情况下创建这种电影类型概率吗?
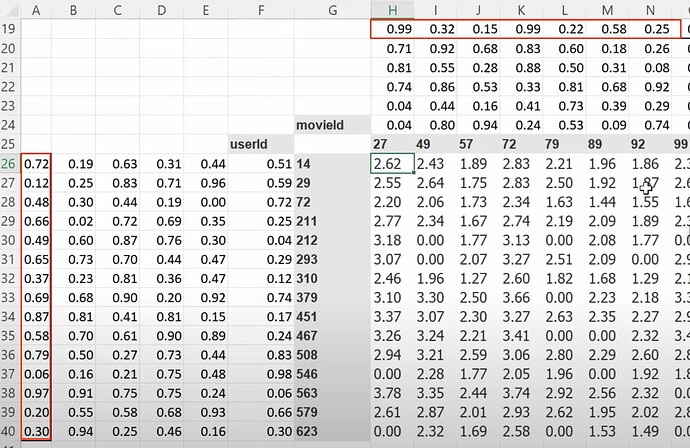
- 什么是潜在因子(latent factors)?如果我对电影一无所知,我们可以使用 SGD(随机梯度下降)来找到它们吗?我们可以创建随机的 5 个数字作为一部电影的 5 个潜在因子来描述电影的类型,然后稍后再确定它们吗?我们也能为每个用户创建潜在因子吗?现在如何计算用户喜欢一部电影的概率?(两个潜在因子组之间的矩阵乘法或点积)。

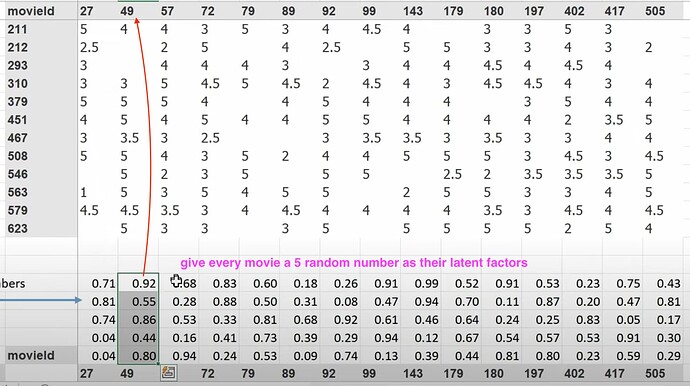
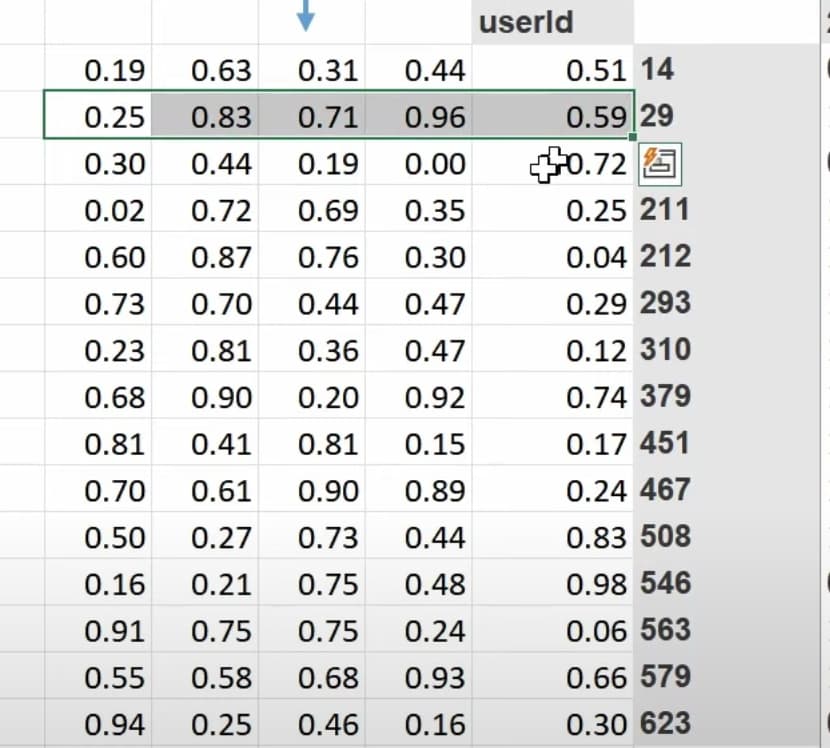
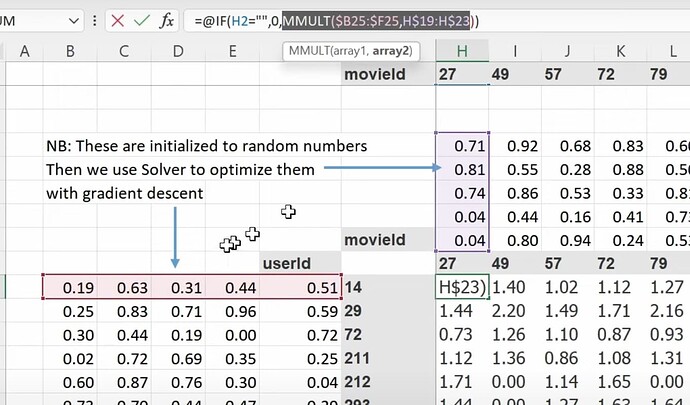
- 现在矩阵乘法或点积可以给出用户喜欢一部电影的预测,所以我们可以将预测与真实标签进行比较。当有缺失标签或数据时怎么办?(我们将预测设为空或零)。我们可以使用 SGD 通过将预测与标签进行比较,并使用损失函数来改进潜在因子吗?如何使用 excel solver 来使用 SGD 和损失函数更新潜在因子?
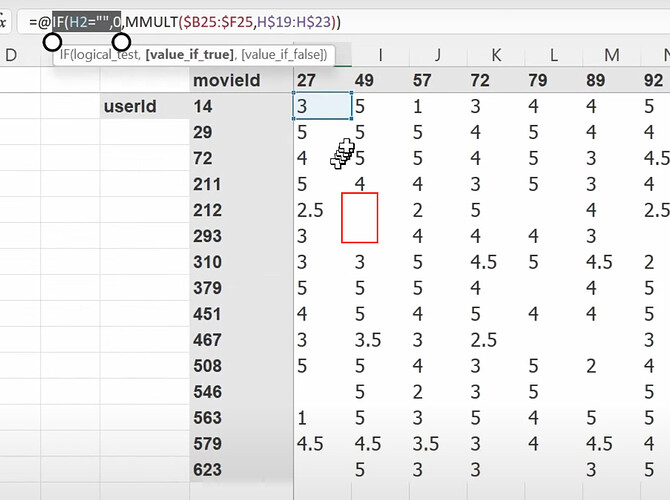
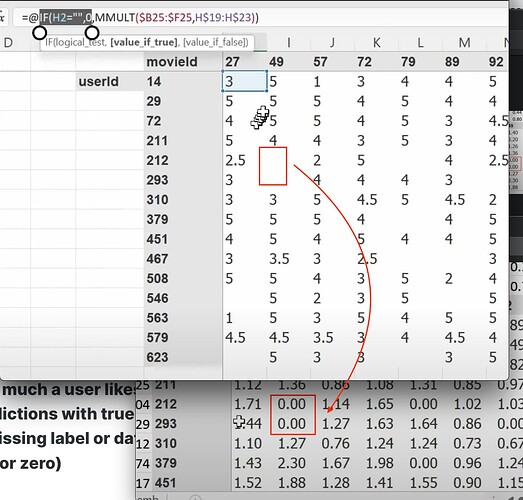
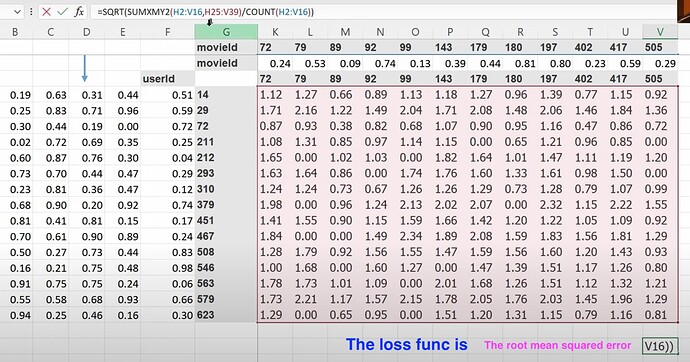
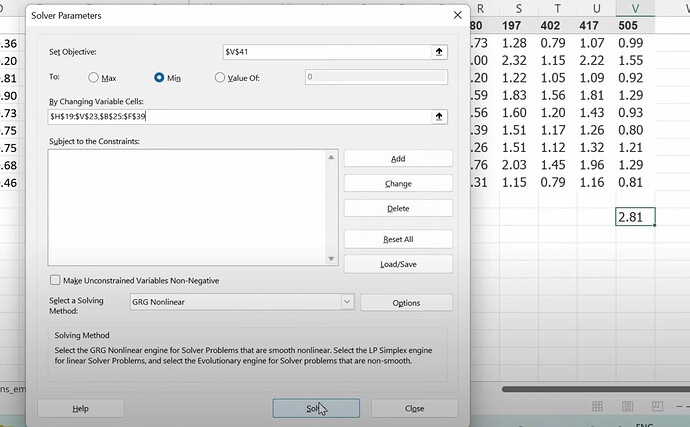
为什么 excel 在计算梯度方面如此慢,即使是小型数据集也是如此?协同过滤的基础是什么?(如果我们知道 A 喜欢 (a, b, c) 并且 B 喜欢 (a, b, c),那么如果 A 喜欢 (d, e),也许 B 也喜欢 (d, e))。- 两个向量之间夹角的余弦与点积是一回事吗?- 由于 pytorch 的数据格式与 excel 不同,我们如何在 pytorch 中做上述事情?数据集在 pytorch 中会是什么样子?
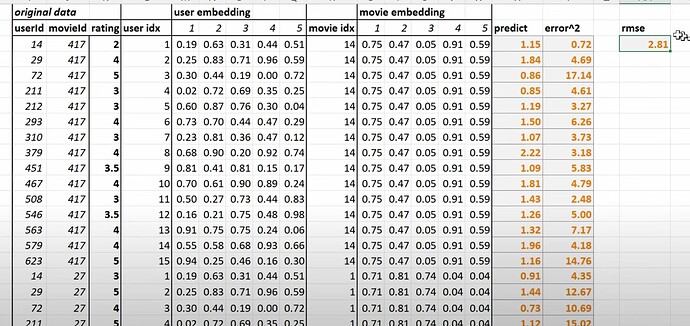
嵌入(Embeddings)
- 什么是嵌入(embedding)?什么是嵌入矩阵、用户嵌入和电影嵌入?(嵌入 = 在数组中查找某物)。一个领域中创造的术语越吓人,这个领域实际上就越不吓人。
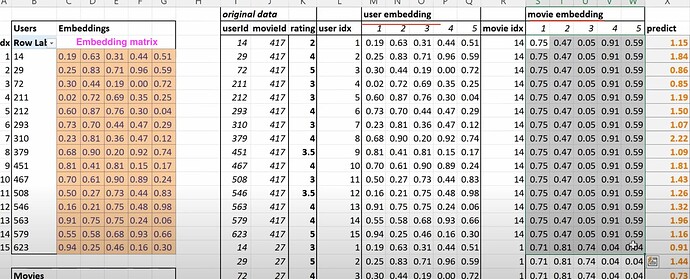
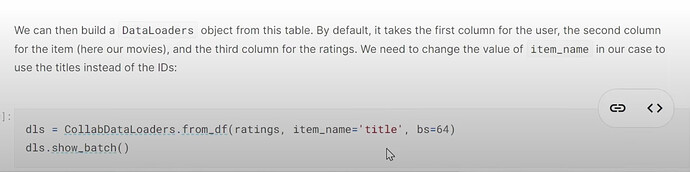
- 在构建 dataloaders 之前,我们的数据集是什么样子的?如何使用
CollabDataloaders.from_df为协同过滤创建一个 dataloaders?它的show_batch是什么样子的?我们如何一起创建用户和电影的潜在因子?
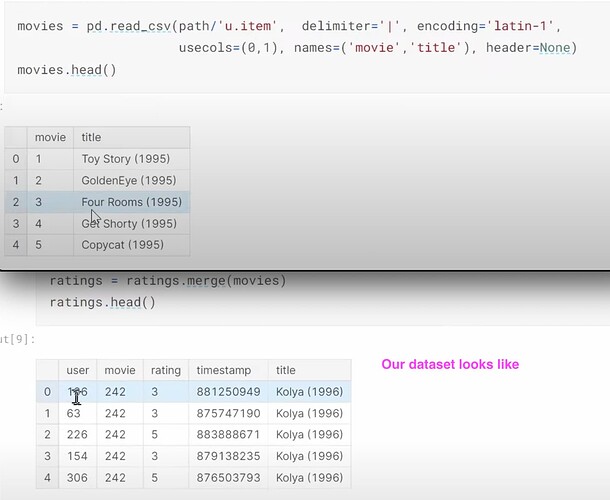
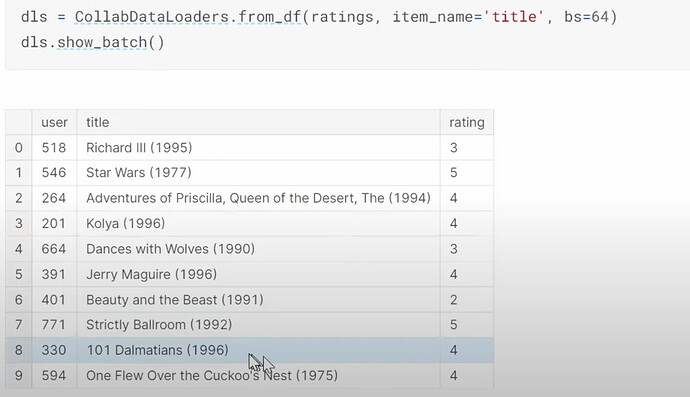

- 在 fastai 中如何选择潜在因子的数量?
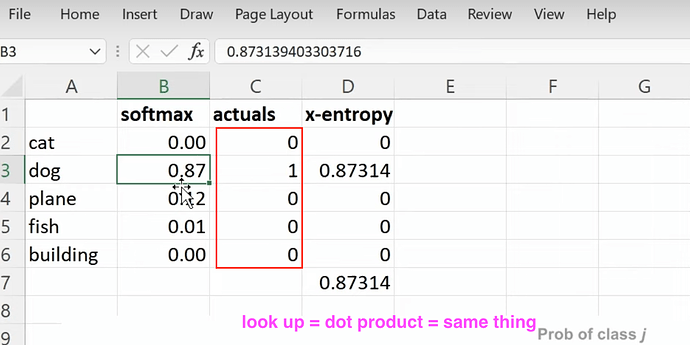
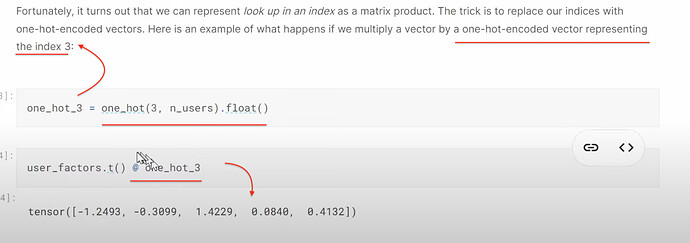
- 如何理解在 excel 中查找潜在因子和与 one-hot 嵌入进行点积实际上是一回事?我们可以将嵌入视为一种计算捷径,用于将某物乘以一个 one-hot 编码向量吗?我们可以将嵌入视为一种数学技巧,用于加速与哑变量的矩阵乘法(无需创建哑变量或 one-hot 编码向量)。
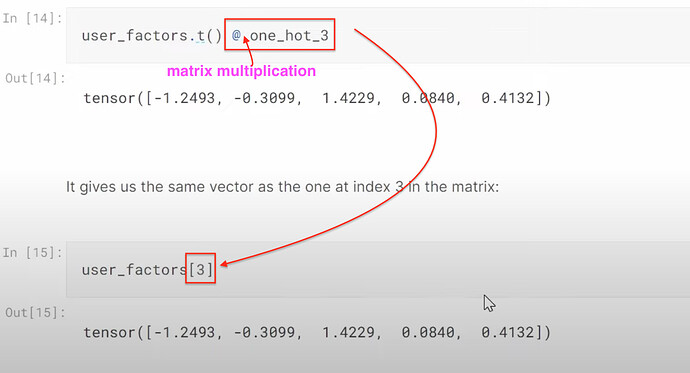
面向对象编程
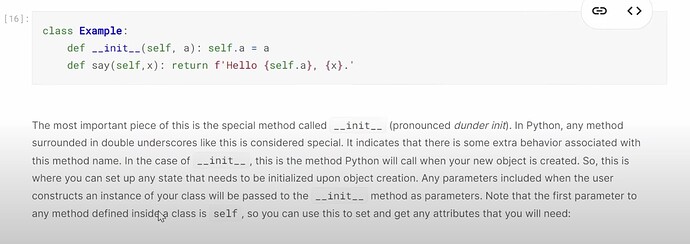
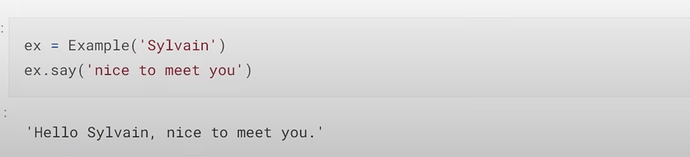
- 如何从头构建一个协同过滤模型?我们如何创建一个类?(因为模型就是一个类)。我们如何通过
__init__初始化一个类对象?__init__是否告诉我们需要提供哪些参数来创建一个类实例?类函数say是做什么的?什么是超类?创建类时把它放在哪里?它给了我们什么?创建类时,pytorch 和 fastai 使用的超类(Module)是什么?DotProduct类是什么样子的?

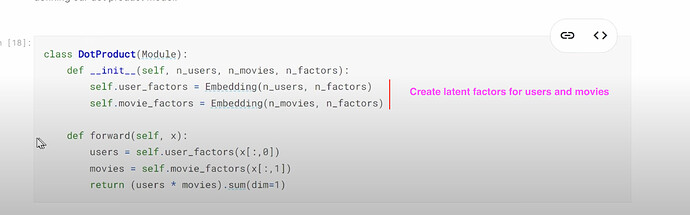
- 如何理解
DotProduct类中的forward函数?.sum(dim=1)是什么意思?(对每一行求和)。

改进协同过滤
- 如何创建一个协同过滤 learner 并开始训练?即使在 CPU 上,训练也很快。
- 为什么上面的协同过滤模型表现不佳?(评分的人是热爱电影的人,他们很少给 1 分,但给出很多高分。然而预测结果却有很多超过 5 分的评分)。回顾 sigmoid 的用法。我们如何对预测结果进行 sigmoid 转换?这个 sigmoid 是如何工作的?为什么我们使用范围上限
5.5而不是5?添加 sigmoid 总是能改善结果吗?

- Jeremy 从数据集中观察到了什么有趣的事情?(有些用户喜欢给所有电影打高分,有些则倾向于不喜欢所有电影)。我们能否在用户和电影的潜在因子中都添加一个偏置值来解释这个有趣的观察结果?如何在协同过滤模型中使用偏置因子?
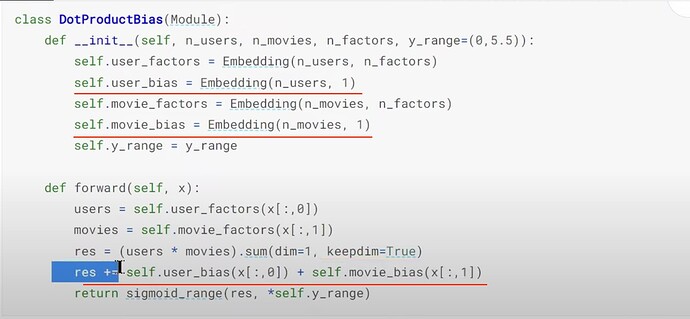
- 为什么带有偏置项的升级模型表现更差了?(过拟合)。
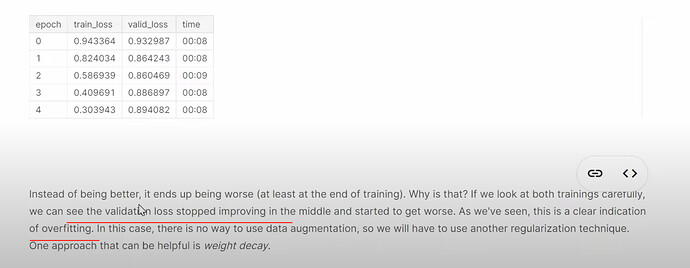
权重衰减
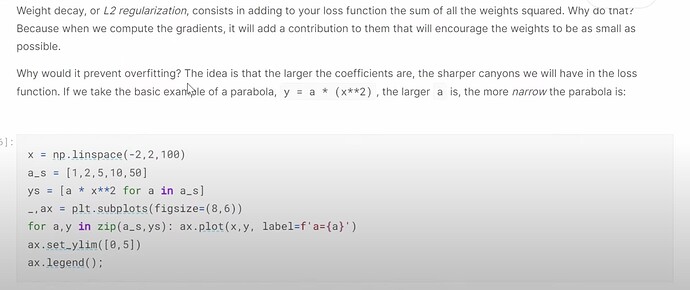
- 什么是权重衰减?它有什么帮助?如何理解权重衰减在解决过拟合问题中的作用?
- 如何在 fastai 代码中实际使用权重衰减?fastai 是否像 CV 一样为协同过滤提供了一个好的默认值?Jeremy 建议如何为自己的数据集找到合适的
wd值?
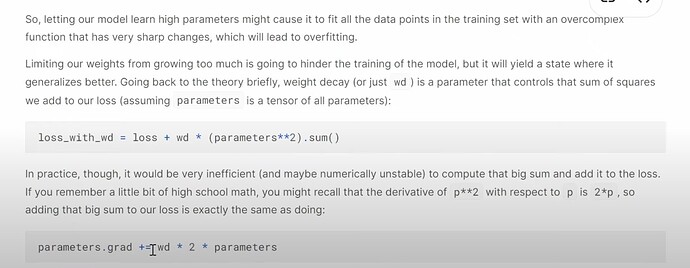
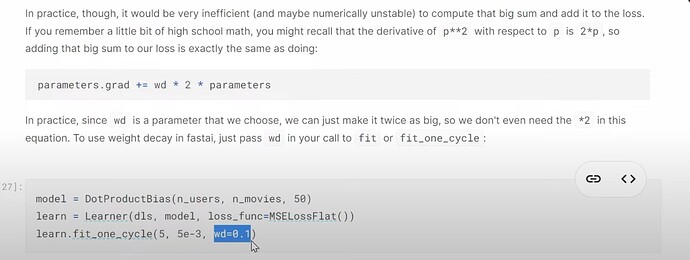
- 什么是正则化?权重值很高或很低有什么问题?权重衰减如何帮助平衡?
- 更多问题:除了 Jeremy 关于潜在因子数量的经验法则外,还有其他规则吗?以及关于平均评分的推荐只在有很多元数据时才可行?